/*
Copyright (c) 2011, Cryst.
All rights reserved.
Redistribution and use in source and binary forms, with or without modification,
are permitted provided that the following conditions are met:
* Redistributions of source code must retain the above copyright notice, this
list of conditions and the following disclaimer.
* Redistributions in binary form must reproduce the above copyright notice,
and/or other materials this list of conditions and the following disclaimer
in the documentation provided with the distribution.
* Neither the name of the Cryst nor the names of its contributors may be used
to endorse or promote products derived from this software without specific
prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND
ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED.
IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT,
INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING,
BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF
LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE
OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED
OF THE POSSIBILITY OF SUCH DAMAGE.
*/
/*
csv(comma-separated values)や、tab を区切り記号として作成されたスプレッドシート
用データの縦横を入れ替えるプログラム。
引数に指定されたファイル名を左から右方向に連続処理していく。途中に区切り記号を切り替
えるオプションが指定された場合は、以降の処理では指定された文字を区切り文字として使用
する。(何回出現してもその度に切り替えられる)
出力ファイル名は入力ファイル名に、html 形式での出力時は、_replace.htm が付加され、
csv 形式での出力時は、_replace.csv を付加した名前が使用される。
*/
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<sys/stat.h>
// gcc -O3 -W -Wall -o replaceAspect replaceAspect.c
#define BUFF_MAX (4096) // MAX_PATH is better.
#define DELIMITERISTAB ((unsigned char)'\t')
#define DELIMITERISCMA ((unsigned char)',')
unsigned char delimiter=DELIMITERISTAB ;
enum TYPE { HTML, CSV };
enum MODE { NORMAL, REPLACE };
enum ANSWER { YES, NO };
// 指定された大きさの、二次元配列を動的に作成する
void **alloc2Darray( int sizeOfUnit, int lx, int ly )
{
register void **d, *base ;
register int i, s=sizeOfUnit, llx=lx, lly=ly ;
if( (sizeOfUnit<1) || (lx<1) || (ly<1) ) return NULL;
if( (d=(void **)calloc(1,ly*sizeof(void *)+(lx*ly*sizeOfUnit))) == NULL) return NULL;
base = (unsigned char *)d + ly*sizeof(void *);
for( i=0; i<lly; i++ ) d[i] = (void *)((unsigned char *)base + llx*s*i);
return d;
}
// 使用方法を表示して処理を終了する
void usage(char *funcname)
{
register int i ;
for(i=strlen(funcname)-1; i>=0 && funcname[i]!='/' && funcname[i]!='\\'; i--) ;
fprintf( stderr, "\nUsage: %s {-c|-t|-n|-h|-s|file_name}+\n\n", &funcname[i+1] );
if(delimiter==DELIMITERISTAB) {
fprintf( stderr, "\toption -c: The delimiter changes to comma.\n");
fprintf( stderr, "\toption -t: The delimiter changes to tab. (default)\n");
} else if(delimiter==DELIMITERISCMA) {
fprintf( stderr, "\toption -c: The delimiter changes to comma. (default)\n");
fprintf( stderr, "\toption -t: The delimiter changes to tab.\n");
}
fprintf( stderr, "\toption -n: The next file result will not replace.\n");
fprintf( stderr, "\toption -h: The next file result write as html format.\n");
fprintf( stderr, "\toption -s: The next file result write to stdout.\n");
fprintf( stderr, "\tfile_name: File name to replace the rows and columns.\n\n");
exit(1);
}
inline void str2htmlstr(register FILE *fp, register char *s)
{
fprintf(fp,"<td>") ;
for(; *s; s++ ) { // ASCII ONLY
if ( *s==' ' ) fprintf(fp," ") ;
else if( *s=='"' ) fprintf(fp,""") ;
else if( *s=='&' ) fprintf(fp,"&") ;
else if( *s=='<' ) fprintf(fp,"<") ;
else if( *s=='>' ) fprintf(fp,">") ;
else fputc(*s, fp) ;
}
fprintf(fp,"</td>\n") ;
}
// 二次元配列で管理された文字列を縦横の位置関係を保持した状態で出力する
void array_out( char ***a, int type, FILE *fp, int lx, int ly, int delimiter)
{
register int x, y ;
if( type==HTML ) { // html 形式で出力する
fprintf( fp, "<html lang=\"ja\"><head>\n<title></title>\n</head><body>\n");
fprintf( fp, "<table border=\"1\" cellpadding=\"2\" cellspacing=\"2\">\n");
fprintf( fp, "<tbody>\n");
for( y=0; y<ly; y++ ) {
fprintf( fp, "<tr>\n" );
for( x=0; x<lx; x++ ) {
if( a[y][x]==NULL || strlen(a[y][x])==0 ) fprintf(fp,"<td> </td>\n");
else str2htmlstr(fp,a[y][x]);
}
fprintf( fp, "</tr>\n\n" );
}
fprintf( fp, "</tbody>\n</table>\n" );
fprintf( fp, "</body></html>\n" );
} else if( type==CSV ) { // csv 形式で出力する
for( y=0; y<ly; y++ ) {
for( x=0; x<lx; x++ ) {
fprintf(fp, "%s", a[y][x]!=NULL ? a[y][x] : "");
if ( x<(lx-1) ) fprintf(fp, "%c", delimiter );
}
fprintf( fp, "\n" );
}
} else fprintf( stderr, "NOT support.\n");
}
// 二次元配列で管理された文字列を縦横の位置関係を反転した状態で出力する
void array_replace_out( char ***a, int type, FILE *fp, int lx, int ly, int delimiter)
{
register int x, y ;
if( type==HTML ) { // html 形式で出力する
fprintf( fp, "<html lang=\"ja\"><head>\n<title></title>\n</head><body>\n");
fprintf( fp, "<table border=\"1\" cellpadding=\"2\" cellspacing=\"2\">\n");
fprintf( fp, "<tbody>\n");
for( y=0; y<lx; y++ ) {
fprintf( fp, "<tr>\n" );
for( x=0; x<ly; x++ ) {
if( a[x][y]==NULL || strlen(a[x][y])==0 ) fprintf(fp,"<td> </td>\n");
else str2htmlstr(fp,a[x][y]);
}
fprintf( fp, "</tr>\n\n" );
}
fprintf( fp, "</tbody>\n</table>\n" );
fprintf( fp, "</body></html>\n" );
} else if( type==CSV ) { // csv 形式で出力する
for( y=0; y<lx; y++ ) {
for( x=0; x<ly; x++ ) {
fprintf(fp, "%s", a[x][y]!=NULL ? a[x][y] : "");
if ( x<(ly-1) ) fprintf(fp, "%c", delimiter );
}
fprintf( fp, "\n" );
}
} else fprintf( stderr, "NOT support.\n");
}
void file_name_is( char *name, int size, int type, int mode, char *base)
{
if (type==HTML && mode==NORMAL) snprintf(name, size, "%s_normal.htm", base);
else if (type==HTML && mode==REPLACE) snprintf(name, size, "%s_replace.htm", base);
else if (type==CSV && mode==NORMAL) snprintf(name, size, "%s_normal.csv", base);
else snprintf(name, size, "%s_replace.csv", base);
}
int main(int argc, char *argv[])
{
register FILE *fp ;
register int i, j, rows, columns, size ;
unsigned char *raw=NULL ;
struct stat fileInfo ;
int mode=REPLACE, type=CSV, standard_out=NO ;
char fname[BUFF_MAX] ;
if ( argc==1 ) usage(argv[0]) ;
for( i=1; i<argc; i++ ) {
if( argv[i][0] == '-' ) {
//引数の解析
if((j=strlen(argv[i]))!=2)
fprintf(stderr,"A invalid option was ignored. '%s'\n",argv[i]);
else if ( argv[i][1] == 's' ) standard_out=YES ;
else if ( argv[i][1] == 'n' ) mode=NORMAL ;
else if ( argv[i][1] == 'h' ) type=HTML ;
else if ( argv[i][1] == 'c' ) delimiter=DELIMITERISCMA ;
else if ( argv[i][1] == 't' ) delimiter=DELIMITERISTAB ;
else fprintf(stderr, "A invalid option was ignored. '%s'\n", argv[i]) ;
continue ;
} else if ( (fp=fopen(argv[i],"rb")) == NULL ) {
//引数で指定されたファイルの読み込み
fprintf( stderr, "'%s' open error.\n", argv[i]); continue ;
} else if ( fstat(fileno(fp), &fileInfo) != 0 ) {
fprintf( stderr, "'%s' stat error.\n", argv[i] ); fclose(fp) ; continue ;
} else if( (raw=(unsigned
char *)calloc(1,fileInfo.st_size+8)) == NULL ) {
fprintf( stderr, "Couldn't allocate memory.\n" ) ; fclose(fp) ; continue ;
} else if ( fread(raw, fileInfo.st_size, 1, fp) != 1 ) {
fprintf( stderr, "'%s' read error.\n", argv[i] ); fclose(fp) ;
} else { //
ファイルサイズより8バイト大きな領域を確保して、ファイルを読み込んだ状態
fclose(fp) ; //
'\0'文字用の1バイト分あれば良いがおまけで8バイトを確保
size=fileInfo.st_size;
file_name_is( fname, sizeof(fname), type, mode, argv[i]) ;
rows=columns=0;
// for line feed code
¥r を処理する
register int temp=0, r=0, n=0;
for( j=0; j<size; j++ ) {
if( raw[j]=='\r' ) r++;
if( raw[j]=='\n' ) n++;
}
temp=(n==0 && r>0)?'\n':'\0';
for( j=0; j<size; j++ ) if(raw[j]=='\r') raw[j]=temp;
// array size check
必要な配列領域の大きさを確認する
for( j=0, temp=0; j<size; j++ ) {
if( raw[j]==delimiter ) temp++;
else if( raw[j]=='\n' ) {
columns++;
if(temp>rows) rows=temp ;
temp=0;
}
}
rows++;
columns++;
// data bind into array
char ***array=(char ***)alloc2Darray(sizeof(char *), rows, columns);
if( array==NULL ) { // rows X columns 個の char * の配列領域を確保
fprintf( stderr, "Couldn't allocate memory for array.\n" ) ;
} else {
register int x=0, y=0 ;
// 読み込んだファイルの、値(文字)の位置を配列に登録
for( j=0, x=0, y=0; j<size; j++ ) {
if( raw[j]=='\n' ) {
y++; x=0;
raw[j]='\0';
} else if( raw[j]!='\0' ) {
if( raw[j]==delimiter ) {
if( x==0 ) array[y][x++]=(char *)&raw[j];
array[y][x++]=(char *)&raw[j+1];
raw[j]=0;
} else array[y][x++]=(char *)&raw[j];
register char w;
for(; j+1<size && (w=raw[j+1])!=delimiter && w!='\0' && w!='\n'; j++);
}
}
for( j=0, temp=0; j<rows; j++ ) if(array[columns-1][j]!=NULL) temp++;
if ( temp==0 ) columns--;
// replace the rows and columns
if ( standard_out==YES ) {
// 配列に登録された値を、指定に従い出力する
if(mode==NORMAL) {
array_out( array, type, stdout, rows, columns, delimiter) ;
mode=REPLACE;
} else array_replace_out( array, type, stdout, rows, columns, delimiter) ;
standard_out = NO;
type = CSV;
} else if ( (fp=fopen(fname,"wb")) != NULL ) {
if(mode==NORMAL) {
array_out( array, type, fp, rows, columns, delimiter) ;
mode=REPLACE;
} else array_replace_out( array, type, fp, rows, columns, delimiter) ;
type = CSV;
fclose(fp) ;
} else fprintf(stderr, "'%s' open error.\n", fname);
free(array) ;
}
}
free(raw);
}
return 0 ;
}
|
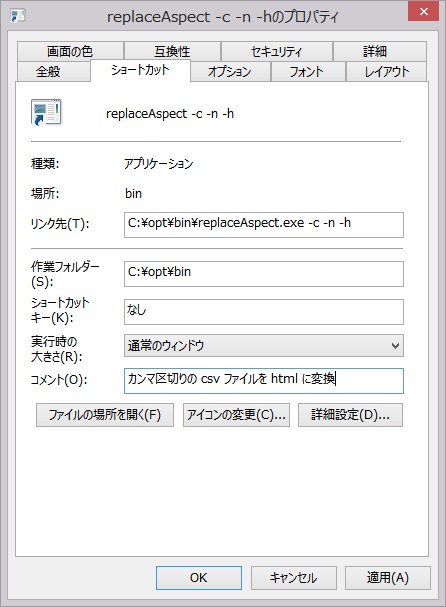
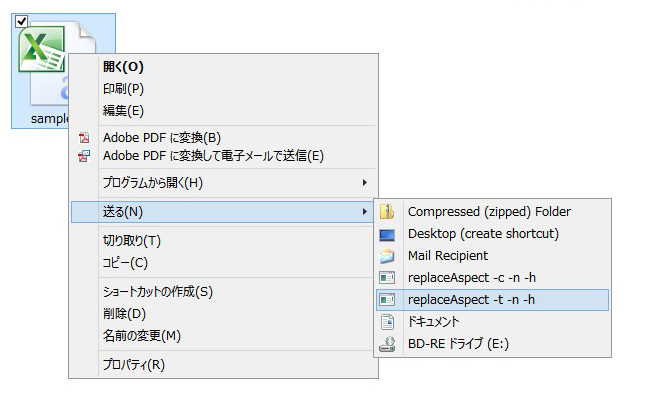
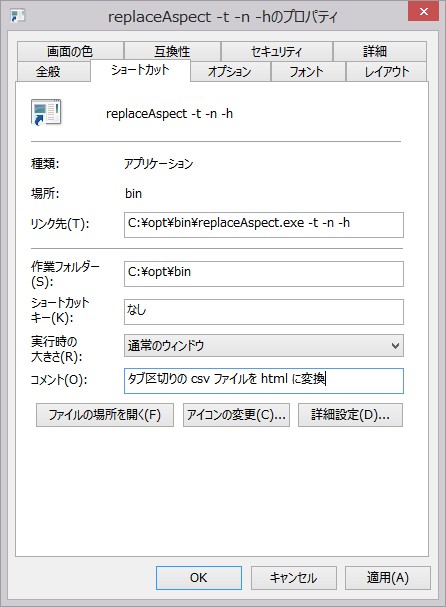 リンク先のコマンドに続けて、引数を定義します。
リンク先のコマンドに続けて、引数を定義します。